Build a Serverless Data Analytics platform using AWS Glue, Athena and QuickSight


Introduction
With ever-increasing data every day it has become crucial for businesses to make meaningful decisions based on the raw data. AWS provides few services to build Business Intelligence without bothering much about high-end and expensive resource provisioning.
I always had trouble keeping track of IPL stats, so I decided a build personalized Dashboard using IPL Complete Dataset (2008-2020) for this demo.
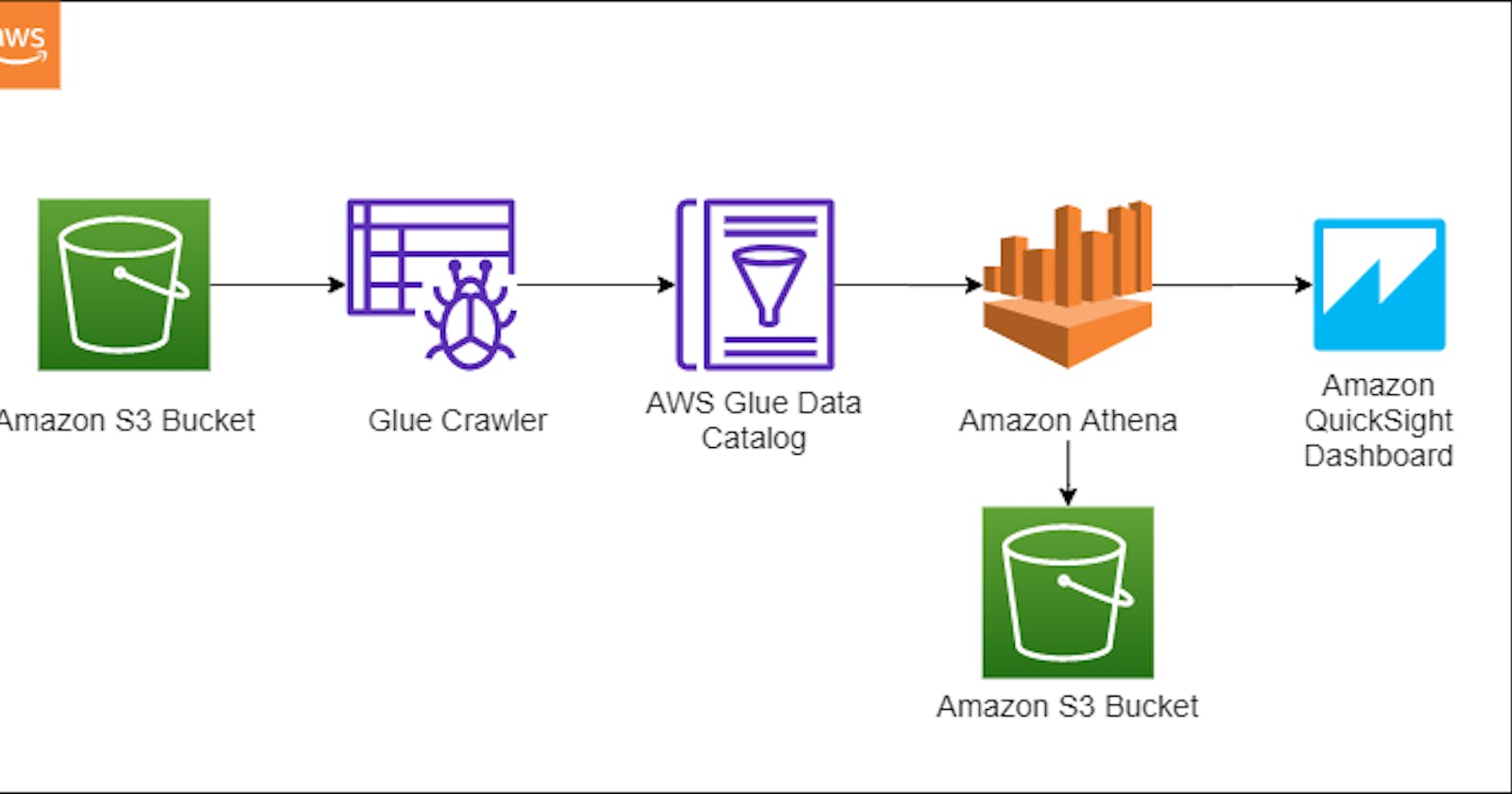
Architecture
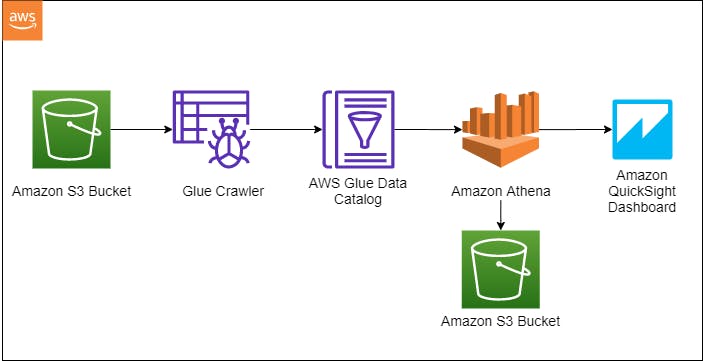
AWS Services
AWS S3
AWS S3 is highly available and infinitely scalable object storage, which makes a perfect option to store all the structured and unstructured data. In this case S3 act as a data lake for our ETL job.
AWS Glue
AWS Glue is a serverless extract, transform, and load (ETL) service to discover process, and prepare data for analysis. AWS Glue Crawler reads raw data from the data lake, understands the schema, and stores the metadata in AWS Glue Data Catalog. Crawlers can run periodically to process new data. For the available dataset, S3 in our case, the data catalog stores table definitions, relevant attributes which can be then processed in AWS Athena.
AWS Crawlers are billed hourly based on the number of Data Processing Units(DPU) used by your crawler to discover data and populate the AWS Glue Data Catalog.
AWS Athena
Athena is a serverless interactive query service to analyze data in S3 using SQL. Athena has in-built integration with AWS Data Glue Catalog. Athena supports a variety of standard data formats, including CSV, JSON, ORC, Avro, and Parquet.
Athena is billed for the number of queries you run. You are charged $5 per terabytes scanned by your queries. You can save about 30-90% cost by compressing, partitioning, and converting your data into columnar formats by introducing a lambda in between.
AWS QuickSight
AWS QuickSight is a serverless, machine learning-powered business intelligence (BI) service that lets you create and publish interactive dashboards. These dashboards can be accessed on any device and embedded in your application, websites, etc. The in-memory engine, SPICE(Super-fast, Parallel, In-memory Calculation Engine) allows blazing fast response time
AWS QuickSight provides two months free trial for up to four users with 10 GB/user SPICE capacity. After that, it is billed per user for a standard or enterprise edition based on your need. AWS QuickSight Pricing is still way less than other BI tools.
Getting Started
Data Lake
Create two S3 buckets, one to store raw datasets and the other to store query results of Athena.
Crawler
Go to crawler console of AWS and click on Add a crawler
- Specify source type
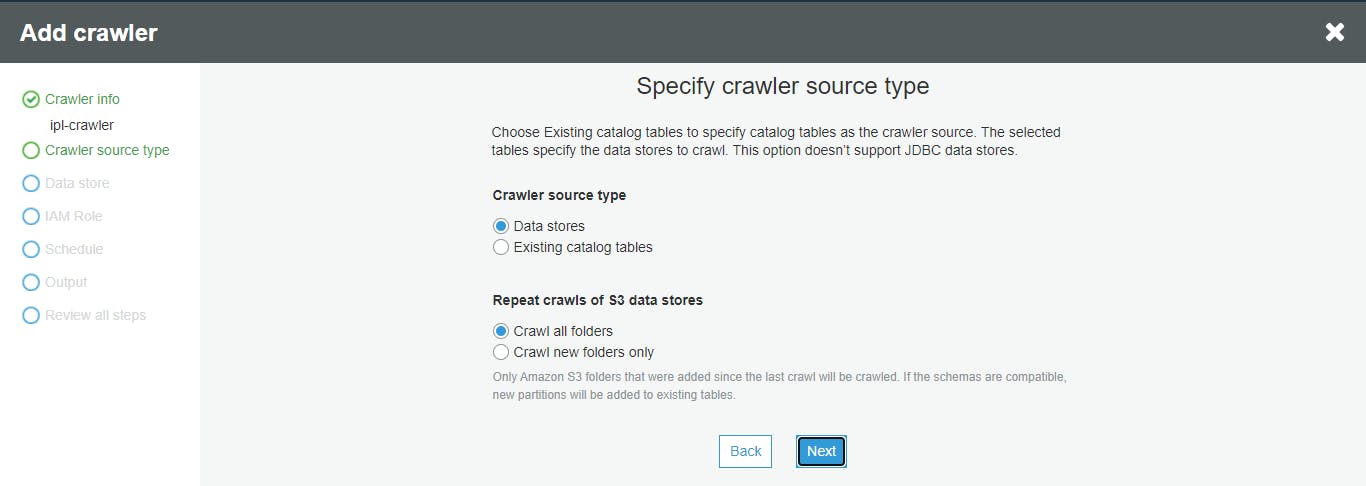
- Add Datastore as S3 location and skip add another data store option in next stage
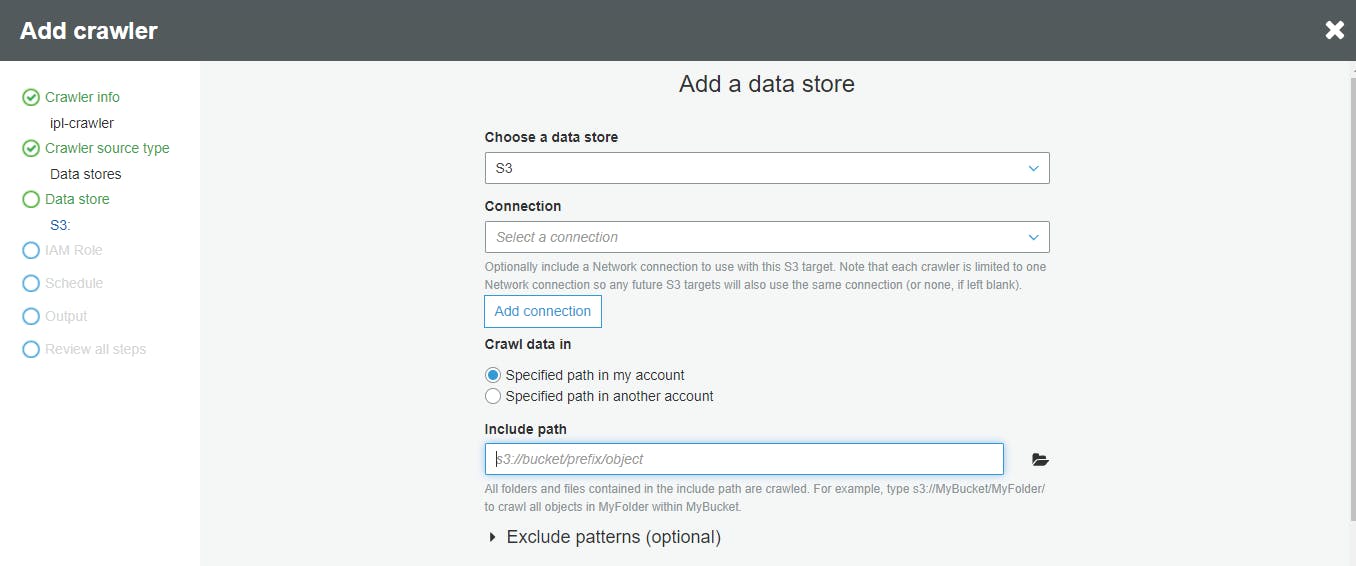
- Create an IAM role
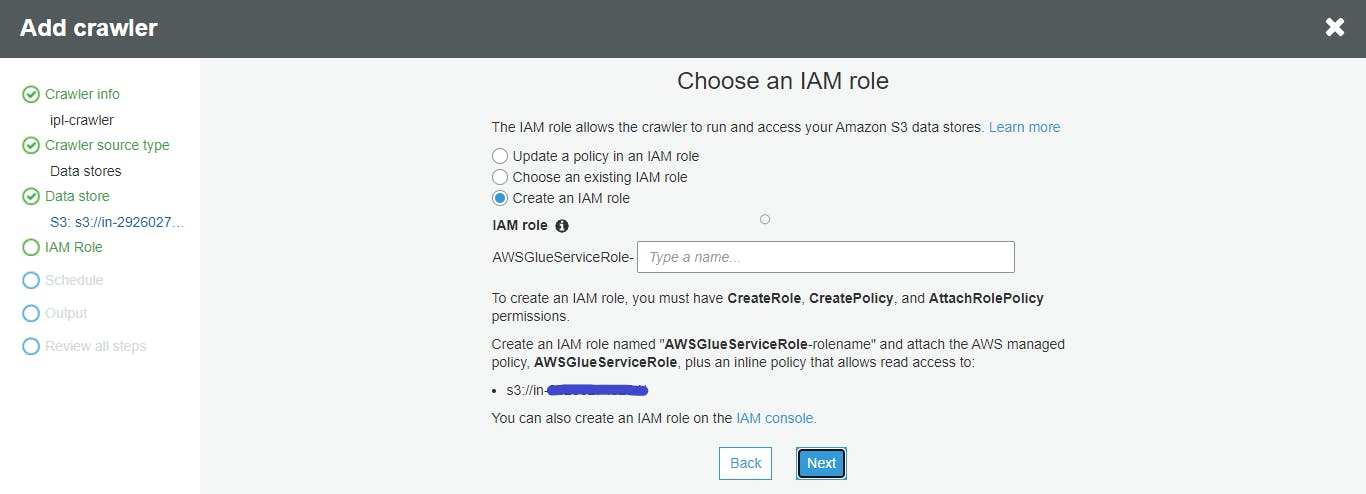
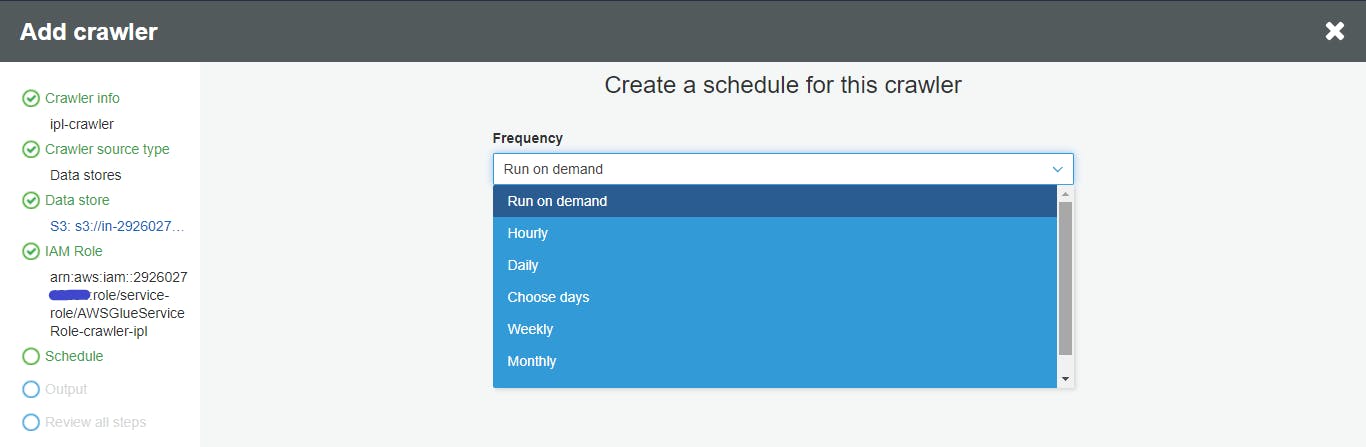
- Create a scheduler
The crawler can be scheduled to run based on data update frequency in S3.
- Configure output
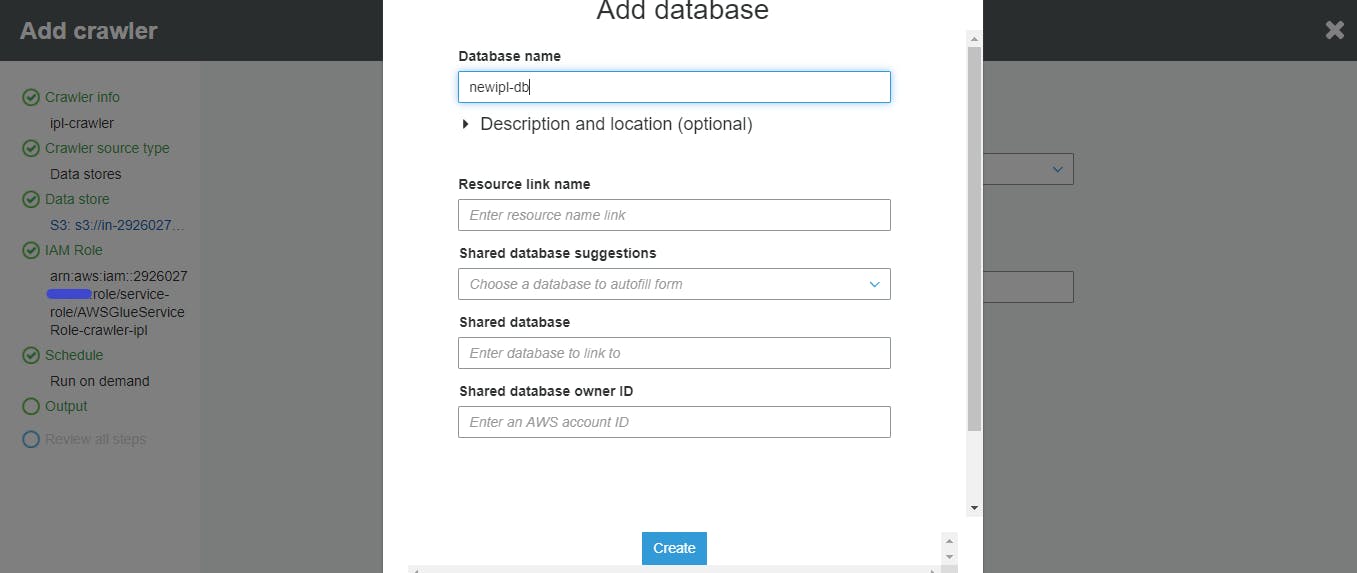
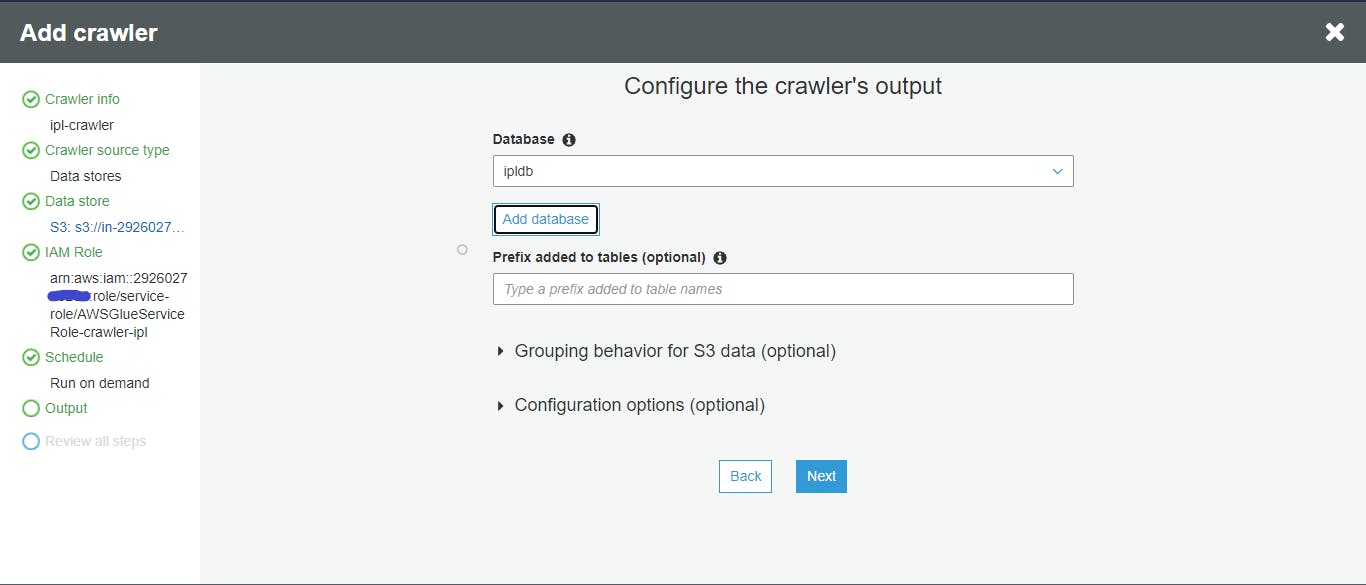 Create a Database where tables schema will be saved
Create a Database where tables schema will be saved
- Review and complete
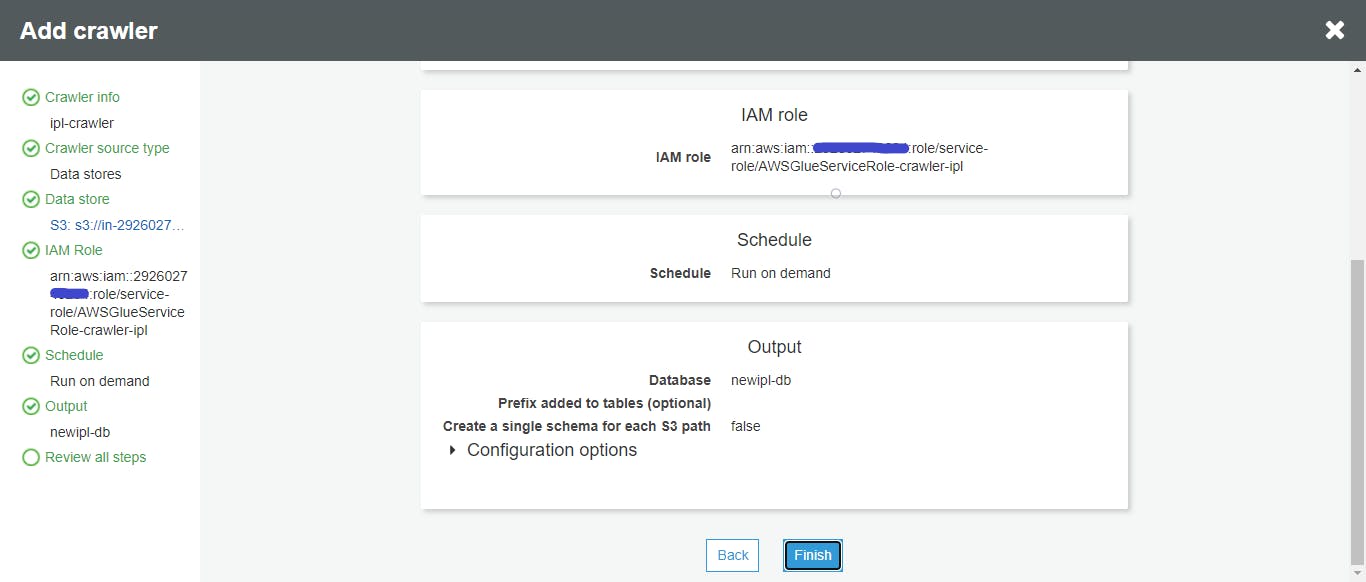
- Run the crawler
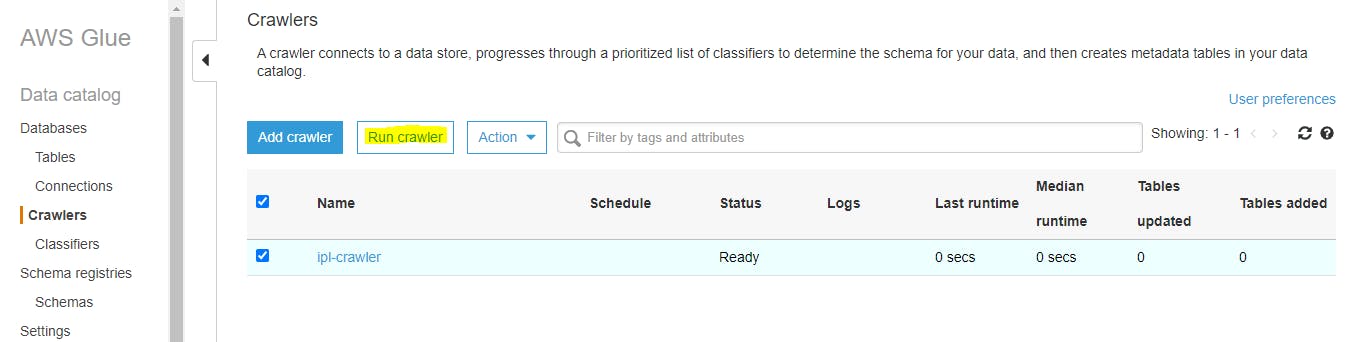
- Observe created Table
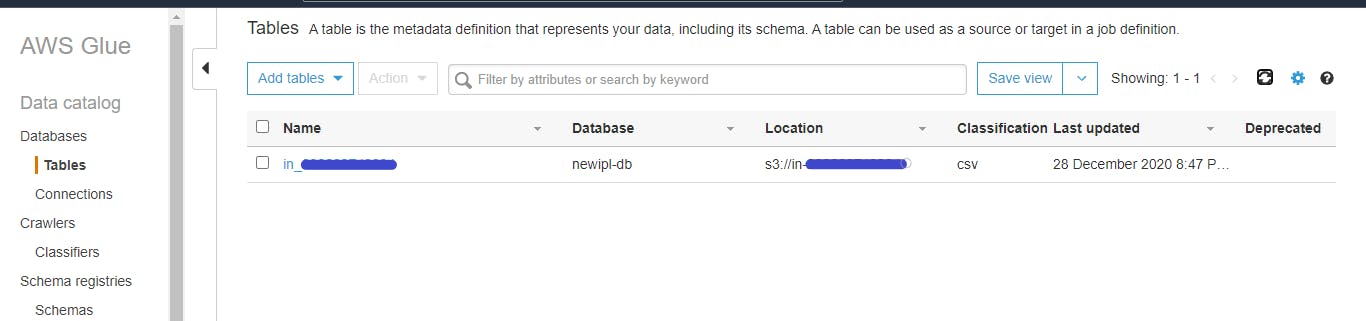 Once crawler has been run, it will create a table with proper schema for raw data from S3 bucket
Once crawler has been run, it will create a table with proper schema for raw data from S3 bucket
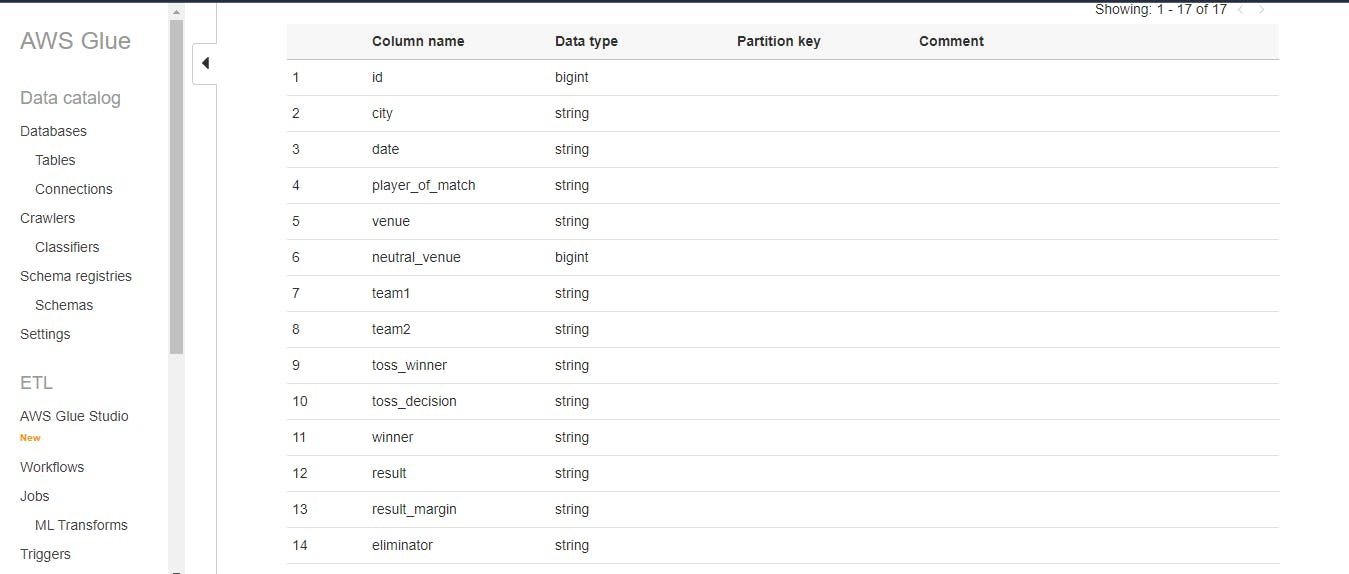
Athena
Go to Athena console
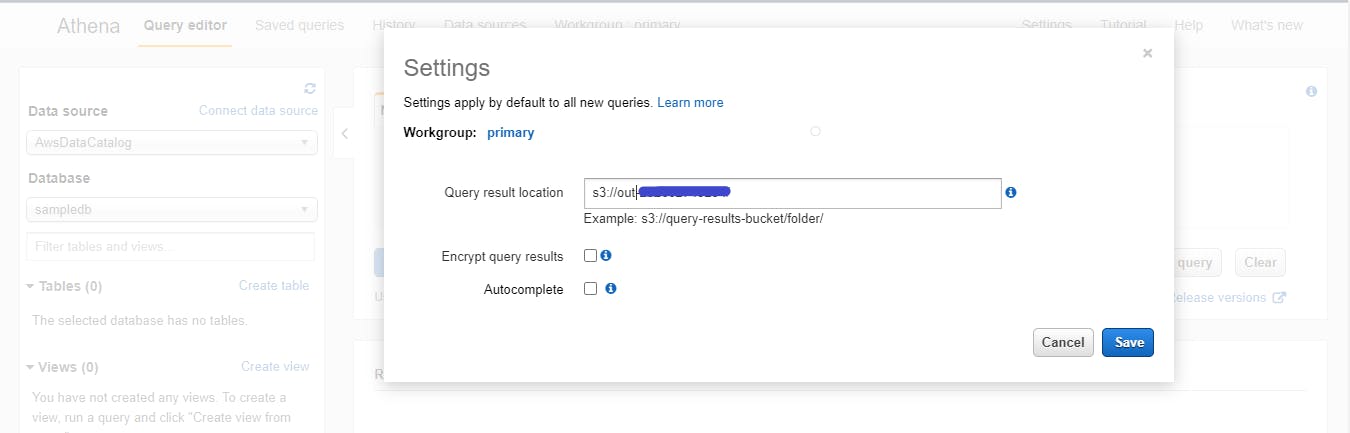
- Athena Query Results setting
Before starting it is important to set up the output location where query results will be saved.
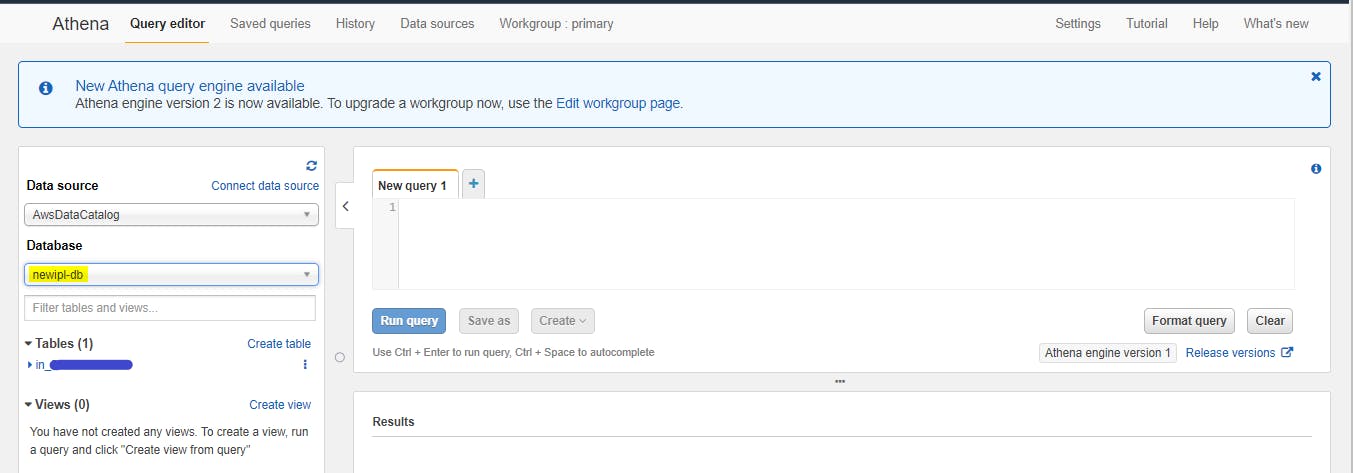
- Select database
Successful creation of Database in previous steps, Athena console will show available Databases and respective Tables
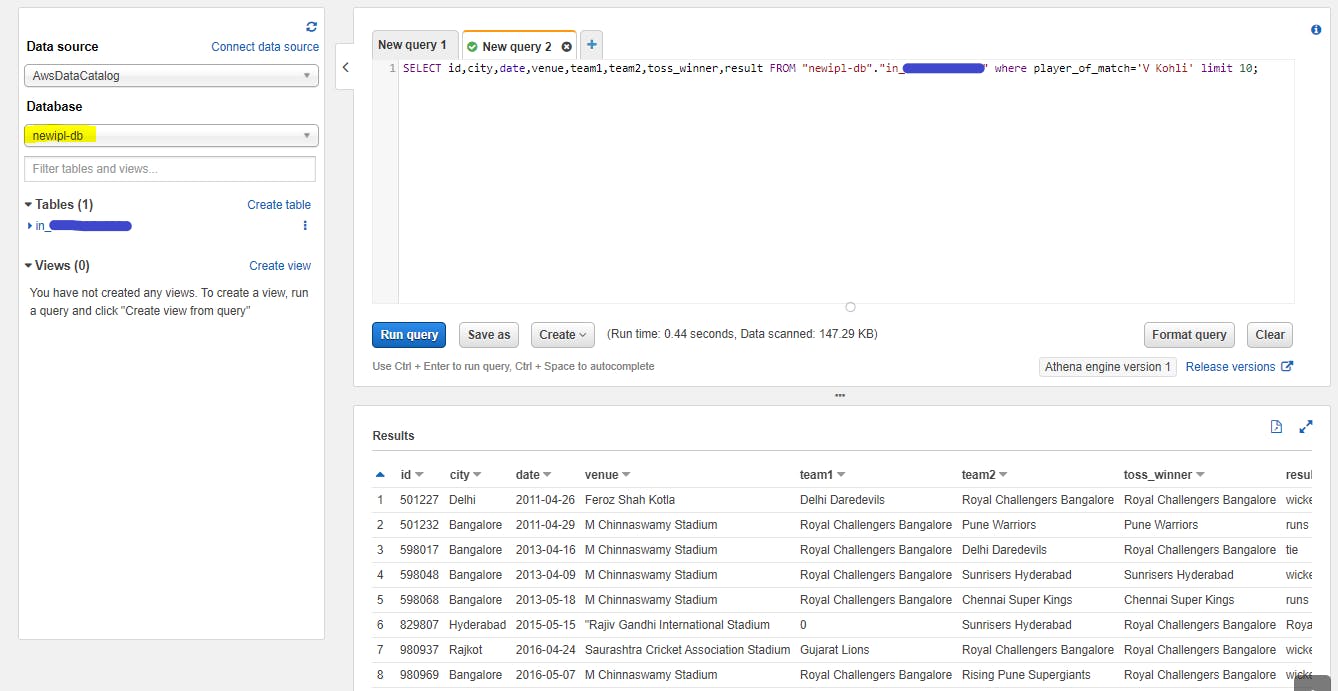
- Query on the Table
Select the Table we created and start querying using SQL.
Quicksight
In Quicksight console
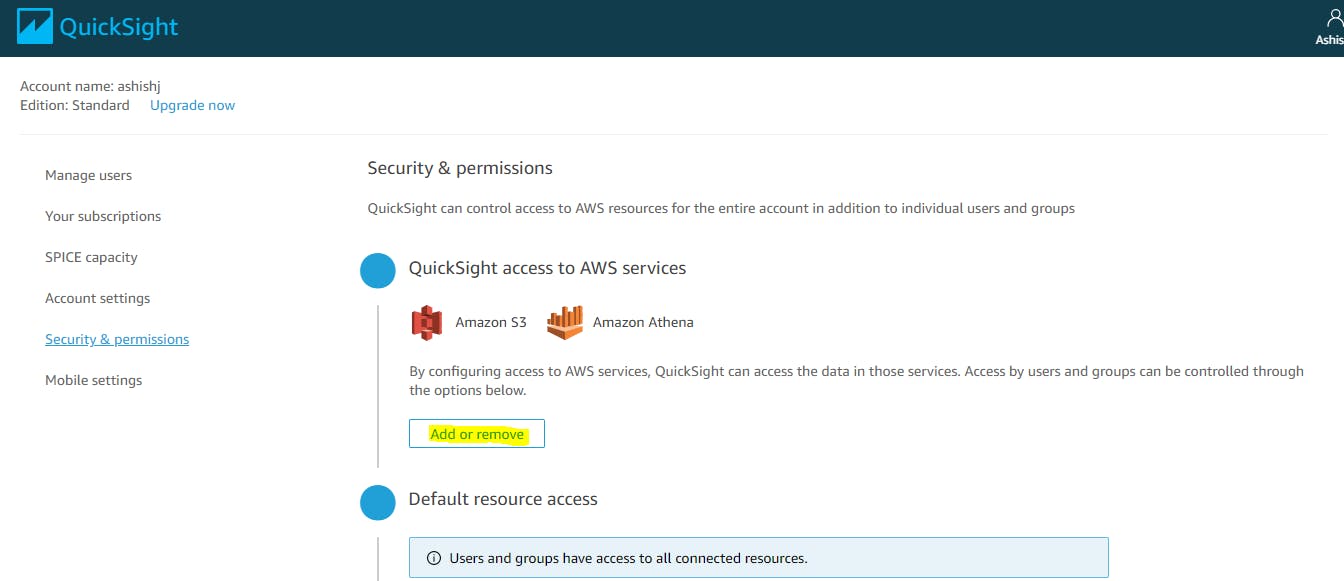
- Security and Permissions
Make sure QuickSight has the necessary permissions to access S3 and Athena
- Select a dataset with Athena as Source
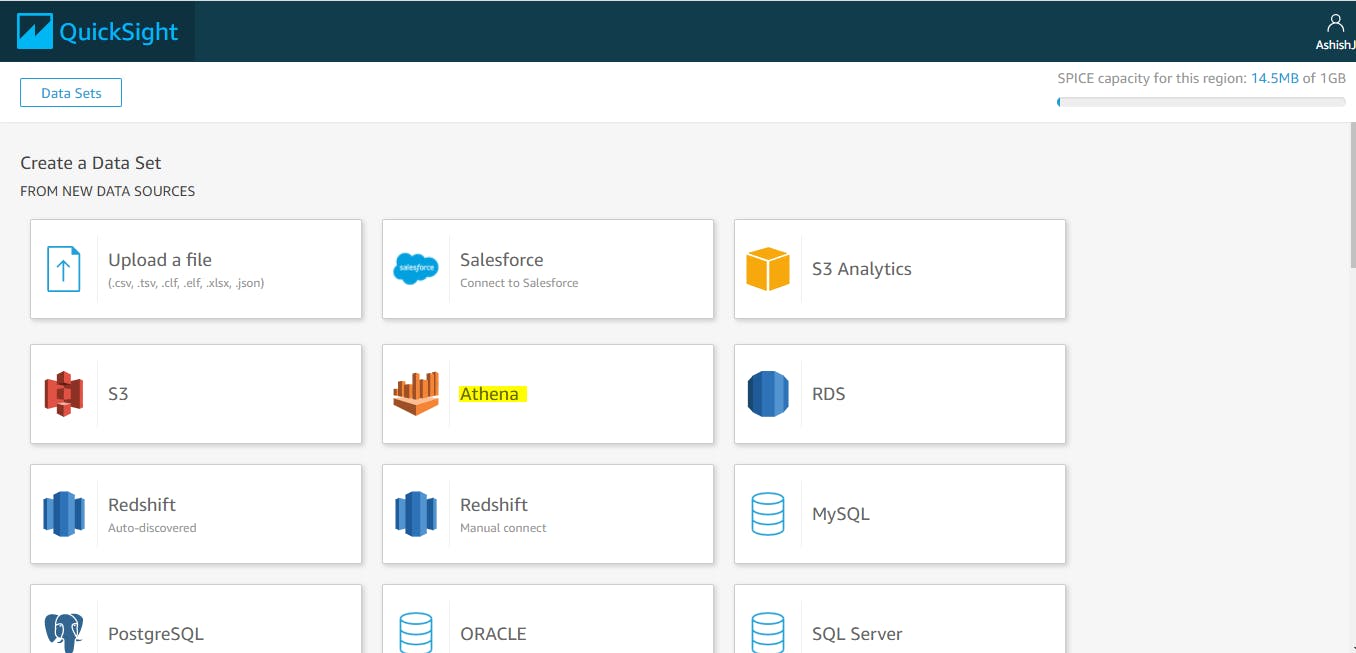
- Choose Table name
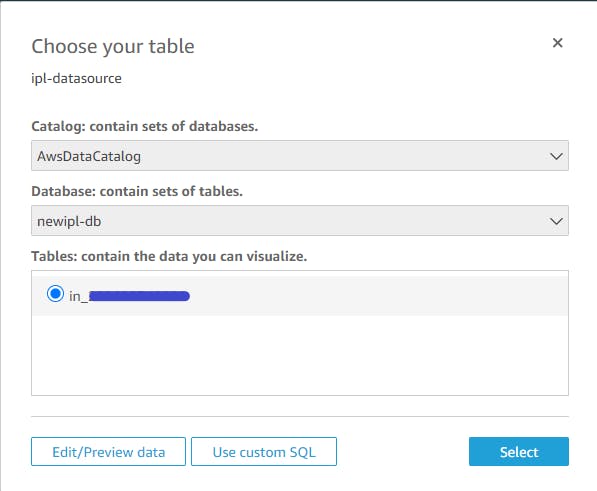
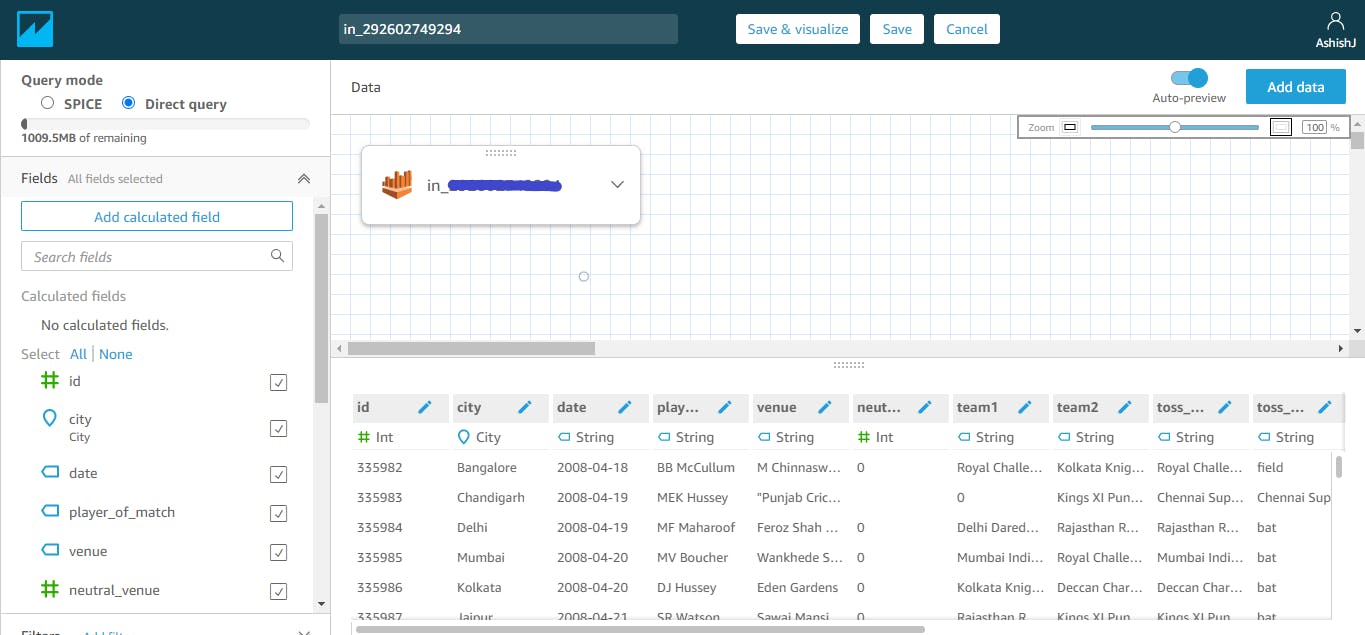
- Preview and Edit Table Schema
Before importing, you can preview the schema and if required can make changes.
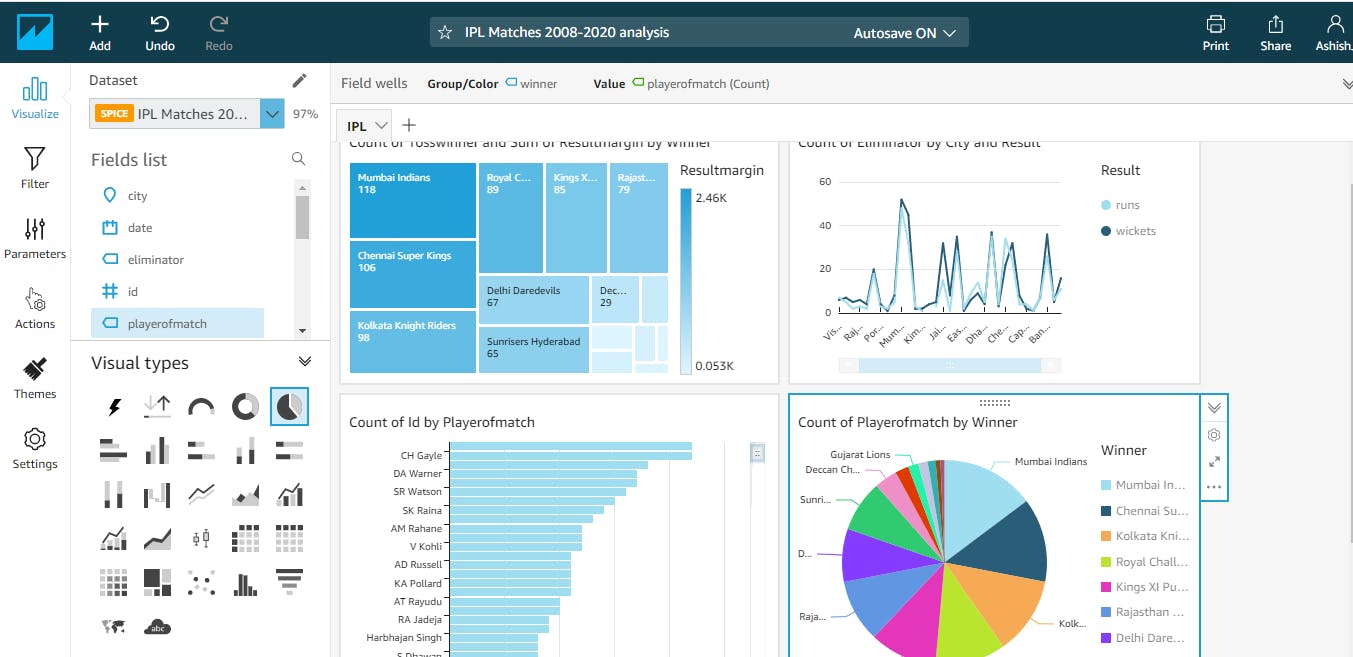
- Create and publish the Dashboard
Cleanup
Release all resources once done to avoid unexpected billing.
Conclusion
The articles help understand how to extract, enrich raw data from a data lake, create schemas, tables using Glue, and query them in Athena. The processed data is then visualized in QuickSight.