Demystifying AWS Lambda Concurrency And How Lambda Actually Scales Under High Traffic?


Introduction
Serverless Applications built around AWS lambda reduces a lot of worries for organizations. They don't have to worry about the administration or the maintenance of the infrastructure . AWS takes care of it including capacity provisioning, auto-scaling, monitoring, and logging. But that's not all, there are some 'gotcha' if you don't understand clearly how lambda scales and how concurrency works in AWS. In this article let's try to understand how concurrency works in Lambda and how to avoid Lambda Throttling because of concurrency reasons.
Lambda Concurrency
In simple terms, concurrency can be defined as the number of instances serving requests at a given time.
When a function is invoked, an execution environment aka an instance is created to process the request. Once the request is completed, the instance stays warm for a while. If another request is made then the existing instance serves the request. But if the first request is not finished and the second request is made then another lambda instance is created, making the concurrency to two and so on.
The ability of Lambda to provision and un-provision instances based on demands is called Auto Scaling. When the traffic is reduced the additional instances are stopped and thus giving a huge advantage in terms of cost as you are only paid for the time the instances were serving the requests.
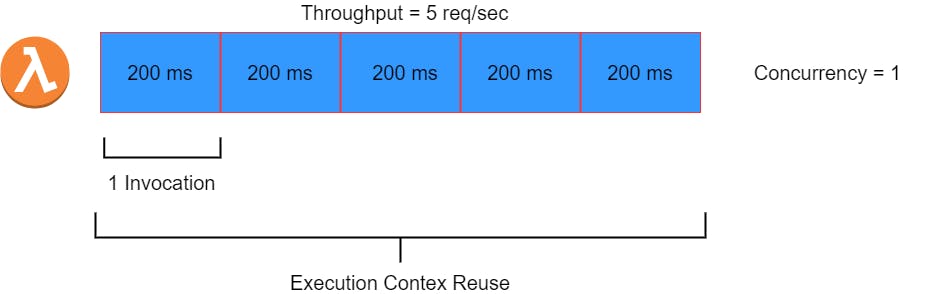
Consider the above example, the lambda takes 200 ms to process a request. If the lambda receives 5 requests per second(1000 ms) then the same instance can handle it. So the concurrency of the lambda function is 1. But if one more request is made within that second then another instance is created thus increasing the concurrency to 2.
Concurrency can be calculated using the below formula-
Avg function execution time (seconds) * avg req/sec = Concurrency estimate
.2 seconds * 5 req/sec = 1
Any configurations defined outside the function's handler can be reused across invocations, shown as Execution Context Reuse in the above diagram. As the execution time increases, the concurrency of the function increases as well. So if the same function took 1 second to process one request and it's receiving 5 req/sec then the concurrency of that function would become 5.
Managing Lambda Concurrency
When we think serverless, there is always an assumption that the lambda can scale to serve thousands of requests per second. It is true but there are regionals concurrency limits on all the lambda functions within a region in your account.
The regional concurrency limit is set to 1000, also called Unreserved Concurrency. All the functions within a region in an account share this quota. If at all the concurrency goes beyond 1000, all the functions will be throttled and requests will fail to process.
It's a soft limit and you can request AWS Support to increase this limit by creating a quota increase request.
There are two types of concurrencies -
- Reserved Concurrency
If you want to allocate a part of unreserved concurrency to a function, you can set it using Reserved Concurrency. No other function can use this concurrency. You can reserve up to total unreserved concurrency minus 100 to any of the functions in your account. So if Unreserved Concurrency is 1000, you can distribute 900 reserved concurrencies to the functions you want, leaving 100 to all remaining functions.
Sometimes you don't want a particular function to use too much concurrency, so you use reserved concurrency to limit its usage from the total concurrency available in the region. If the function needs concurrency beyond its reserved concurrency, it automatically throttles.
If you want to throttle a function, you can set the reserved concurrency to zero. This stops all requests failure until you remove the limit.
- Provisioned Concurrency
Before understanding provisioned concurrency, let's understand what is Cold Starts in Lambda -
When a function is not serving any requests, the instance is terminated and the function goes into an idle state. Next time when the function is invoked, it takes some time to set up and provision the instance. This delay introduced in the execution time of a function is called Cold Start.
There are scenarios where you cannot afford such delays. To overcome this, we may need to keep the function's execution environment always up and running. AWS came up with the concept of Provisioned Concurrency, where we specify how many instances we want to be always warm and ready to serve the requests.
Provisioned concurrency can be assigned up to the function's reserved concurrency or regional quota limits. So you cannot allocate more provisioned concurrency than reserved concurrency of the function.
One important thing to note is, provisioned concurrency has cost implications other than normal lambda pricing. You pay for the amount of concurrency provisioned and for the period of time it is configured. To reduce the cost of provisioned concurrency, you can use auto-scaling to allocate provisioned concurrency for predictive workloads.
Lambda Scaling
So far we know that there is a default unreserved concurrency set to 1000. That means all requests beyond 1000 concurrent execution will throttle. It's a soft limit so we can increase it to Hundreds of thousands based on the traffic your application serves.
Even if you increase the regional quota beyond 1000, there is one more hard limit that may throttle your function. The limit is called the Burst Limit, it varies in different regions between 500 to 3000. After the initial burst, your function can add 500 instances every minute until it reaches reserved concurrency or regional quota. Additional requests within this timeframe will throttle. We will with an example of how Burst Limit works.
Example Scenario
Let's assume you have a simple serverless application with API Gateway, A Lambda and DynamoDB deployed in the us-east-1 region. It has a regional quota of 1000, Burst Limit of 3000 and you haven't increased the regional quota yet.
Baseline defines the application can always serve 1000 concurrent executions.
Now the application starts receiving constant 4000 requests per second with each lambda taking one second to complete. That means the application expects 4000 instances of the function running i.e. the concurrency to be 4000.
Using Default Unreserved Concurrency
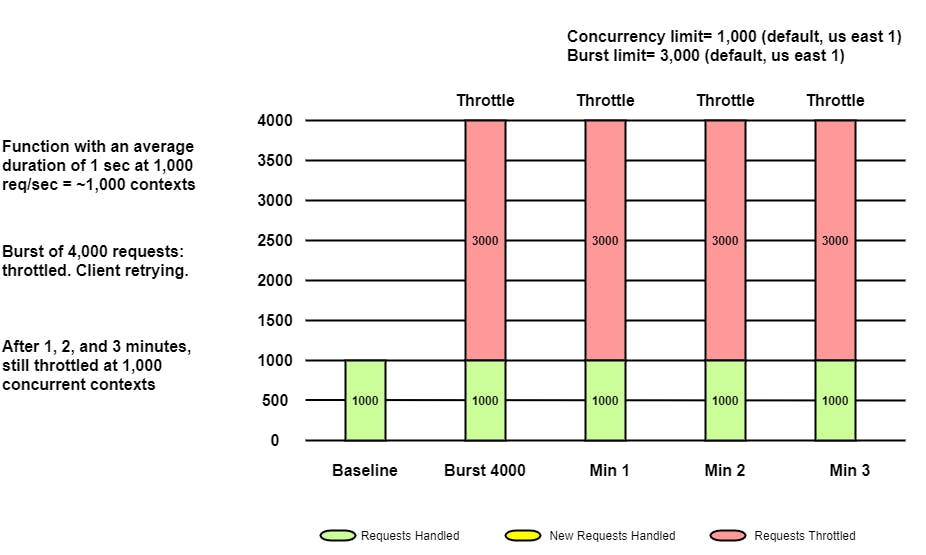 If the application is receiving 4000 requests per second constantly, only 1000 requests per second will be served as it has already hit the regional quota. Only 1000 instances can be provisioned in this case, for all requests that may need additional instances will be throttled.
If the application is receiving 4000 requests per second constantly, only 1000 requests per second will be served as it has already hit the regional quota. Only 1000 instances can be provisioned in this case, for all requests that may need additional instances will be throttled.
As long as the same requests are coming, only 1000 will be served and 3000 will throttle.
Increasing Regional Quota
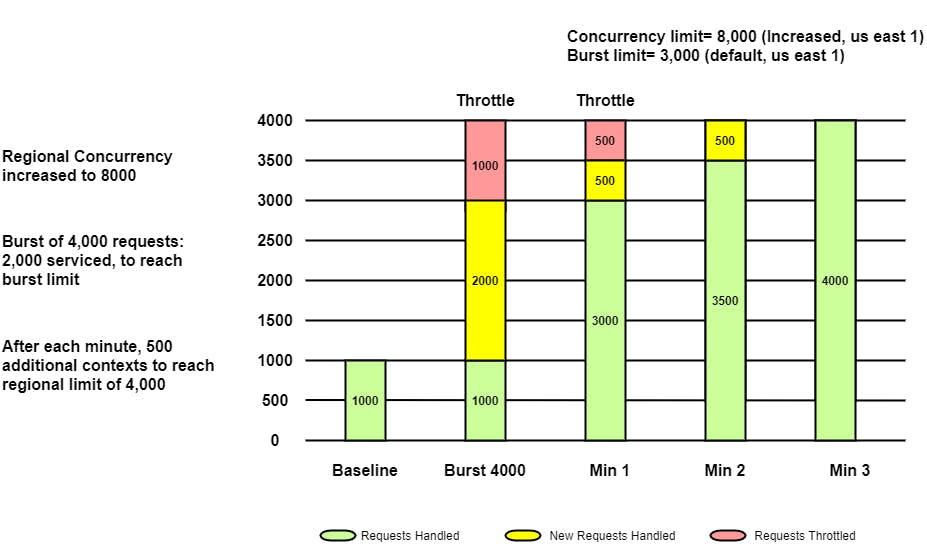
Now that you know your application needs 4000 concurrent executions, you request AWS for a quota increase to 8000(anything beyond 4000). Remember the Burst limit is a hard limit, so even if you have increased the regional quota, it does not guarantee the throttle-free behavior of the application.
Earlier the application was using 1000 instances, now with the increase in regional limit the function bursts out to provision additional instances up to Burst Limit i.e. in the case of us-east-1 is 3000. So additional 2000 instances are provisioned.
For the initial burst of 4000 requests, only 3000(Burst limit) requests are served. At this moment 1000 requests will throttle. After one minute additional 500 instances are provisioned thus serving 3500 requests and throttling 500 requests. At the 2nd minute, 500 more instances are provisioned and all 4000 requests are served.
This is how Burst Limit adds 500 instances every minute to serve the traffic. But it's clear that the lambda is still throttling some requests up to one minute.
Using Provisioned Concurrency
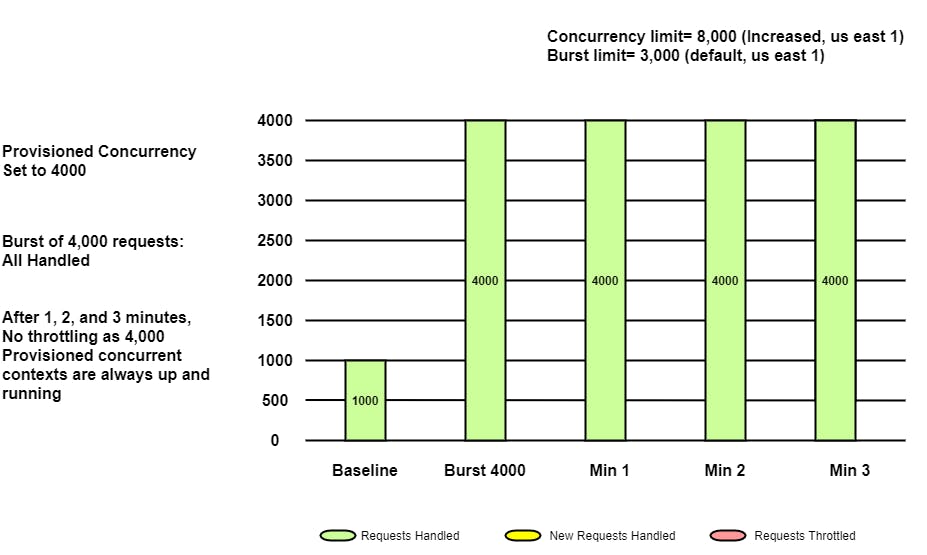
Even after increasing the regional quota, we realized that the Burst limit causing the function to throttle. To overcome this problem, Provisioned concurrency can be used. So if we allocate provisioned concurrency to 4000, at any moment 4000 instances of the lambda are always up and running.
In this case, if the application is receiving 4000 requests per second, all requests will be served without throttling. As it's already beyond Burst Limit, even if the number of requests is increased, those will be served up to the increased regional limit, here 8000.
Conclusion
By understanding how concurrency works in Lambda, what are hard and soft limits, how to increase those limits, and how to use provisioned concurrency, we have learned a better way to build a highly available serverless application without being throttled because of Lambda Concurrency.
References
docs.aws.amazon.com/lambda/latest/dg/config.. docs.aws.amazon.com/lambda/latest/dg/invoca.. aws.amazon.com/blogs/aws/new-provisioned-co..